The Best Vector Database for Stablecog's Semantic Search
Vector databases such as Weaviate, Milvus, Qdrant, Vespa, and Pinecone are a very hot topic in the software industry right now. They essentially allow you to store a representation of any object as a vector (text, images, audio, video, etc. - more on that below). This is a very important tool in AI & Machine Learning applications as it is the base for how prompts are transformed into images, chatbots determine what you’re asking, and much more - including our recent enhancement, semantically searchable images.
What is a vector embedding?
A vector is, essentially, just a list of numbers. The amount of numbers, referred to as dimensions, directly correlates to how much data a vector can represent. In our case the vectors we are interested in storing is a representation of the contextual meaning behind each and every image generated using Stablecog.
When we refer to an “embedding”, we are talking about a lower-dimensional representation of a higher-dimensional object (images and prompts, in our case). Essentially with a 1,024 dimension vector consisting of 32-bit floats, we can represent every image in approximately ~4KB worth of data, while the images themselves contain much more data than that - typically over 100Kb each.
There’s multiple ways to get a vector representation of an image such as Cohere or OpenAI’s CLIP. We have chosen OpenCLIP, which is an open source version of OpenAI’s CLIP - trained on public and free data.
OpenCLIP and Why We Chose It
We believe strongly in open source software, all of the models on Stablecog and all of the source code for Stablecog is completely open source. Modern AI technologies are transforming the way human’s work, how research is conducted, and overall these technologies will change our lives for many generations to come. In our opinion, progress will happen much faster if these technologies are kept open and available for others to continuously study, iterate, and improve. So naturally OpenCLIP was on our radar from the beginning when it came time to choose a model to create vector embeddings with Stablecog images and prompts.
Of course, open source was not the only consideration - we also wanted a model that accurately represented the images created on Stablecog, as well as the prompts used to create them. We chose OpenCLIP ViT-h/14 - LAION 2B which in our experience so far is able to preserve a lot of details in its vector embeddings - making our search results very relevant and accurate.
It is trained with the open source LAION2B data set, and creates vectors that are 1,024 dimensions.
By themselves, these vectors we create aren’t particularly useful. We need a way to store them and run searches against them, which is the exact use case of vector databases.
Vector Databases
Search index databases are not new. There are many options used by some of the largest companies in the world - including but not limited to ElasticSearch, Typesense, and Algolia.
Many of these search-oriented databases also support similarilty searches using vector embeddings, but they were not initially built with that functionality in mind. The solutions talked about below (with the exception of PostgreSQL), are purpose built around storing and searching vector embeddings - it is not just a feature of these databases, but exactly what they were built to do.
In 2023, there is a rising number of “vector databases” which are specifically built to store and search vector embeddings - some of the more popular ones include:
- Weaviate
- Milvus
- Qdrant
- Vespa: We did not try vespa, so cannot give our analysis on it.
- Pinecone: Unlike the other databases, is not open source so we didn’t try it.
We took our time trying various vector search solutions, we needed to create vector embeddings for over 4 million images, as well as every prompt. As a small team of 2, if we made the wrong choice it would be a large setback - delaying the overall progression of our platform.
We tried several options before deciding to use Qdrant. Below is a summary of our experiments and findings, and some more details on how we decided that Qdrant was the correct choice for us.
PostgreSQL pgvector
We use PostgreSQL for the majority of our data storage, so pgvector seemed like a natural first step - with the least amount of engineering effort, given we could store the vector embeddings in the same database we already use.
Initially, our findings were positive:
- Easy to implement
- Search result relevancy was satisfactory.
But as we loaded more data, the downsides led us to continue exploring other options:
- Building indexes was very slow, so experimenting with different settings took awhile
- Search performance was unsatisfactory with many vectors stored (too slow).
Milvus
Milvus is a purpose built vector database. At the time of writing it has 16.4k stars on GitHub. By far more than the other databases we tried.
Things we like about Milvus:
- Open source & Easily self-hostable
- Has a UI component that makes browsing the database easy
- Search results were satisfactory relevant, although potentially a bit less than the other options we tried.
The downsides we found:
- Can only store 1 vector in a schema/collection (we had to choose image, or prompt - not both)
- Resource usage was very high, while all of the vector databases demand relatively high computational power - Milvus was particularly demanding in this regard.
- The docs and SDK availability are very good, however the API responses were not as straight forward - and required extra post-processing to get a format we would want to present to users.
- Quantization index (compressed vector) (IVF_PQ) seemed to hurt search relevancy more than the other options that support quantization.
Weaviate
Weaviate is also a purpose built vector database, and it seems to be rising in popularity incredibly quickly.
Things we like about Weaviate:
- Open source & Easily self-hostable
- Relatively good performance
- Unlike the other options, it has modules which can be installed to automatically compute the embeddings from raw objects. Which positions it as a more convenient all-in-one solution (with all of the others listed, creating the vector embeddings happens externally to the database)
We did run into some drawbacks along the way, though:
- Documentation is harder to navigate than the other options
- We enabled product quantization on our existing collection and it took over 12 hours to re-index the collection
- Note: To be fair, this is a new and experimental feature of Weaviate - which they will certainly improve over time.
- Resource consumption was quite high compared to Qdrant.
- The SDKs and API is not as nice to use as Milvus or Qdrant.
- Like Milvus, it can only store 1 vector in a schema/collection.
Qdrant - Our Favorite
Qdrant is a purpose built vector database, the only one on our list written in Rust. It was the last and final vector database we tried, our initial impressions were extremely positive.
Things we like about Qdrant:
- Multiple vectors in a collection, meaning we can store both prompt embeddings and image embeddings.
- Image embeddings, currently drive our search results
- Prompt embeddings are stored and indexed, allowing us to also enable support for searching prompts in the future easily.
- Scalar Quantization has a noticeable reduction in memory usage, while barely having any impact on search relevancy.
- Resource usage is lower than the other options, quite significantly.
- Documentation is very easy to digest and straight forward.
- API is straight forward and just works how we’d expect it to “common sense”.
- Pagination is straight forward
- It returns the payload fields in a straight forward, ordered way.
- Search is very fast, the highest performing of all options tried.
The main downside we found:
- Lack of built-in authentication, for self-hosted option
- We created sc-qdrant as a result, which makes it easy to deploy a cluster behind an nginx proxy with basic auth.
Semantic Search on Stablecog
User’s can now leverage semantic search in the Stablecog gallery, as well as for all of their own individual generations they created with our platform.
We leverage a custom OpenCLIP API in sc-worker to translate and create embeddings for search queries. This embedding is then used in a similarity search in Qdrant, providing incredibly relevant results based on the search term used.
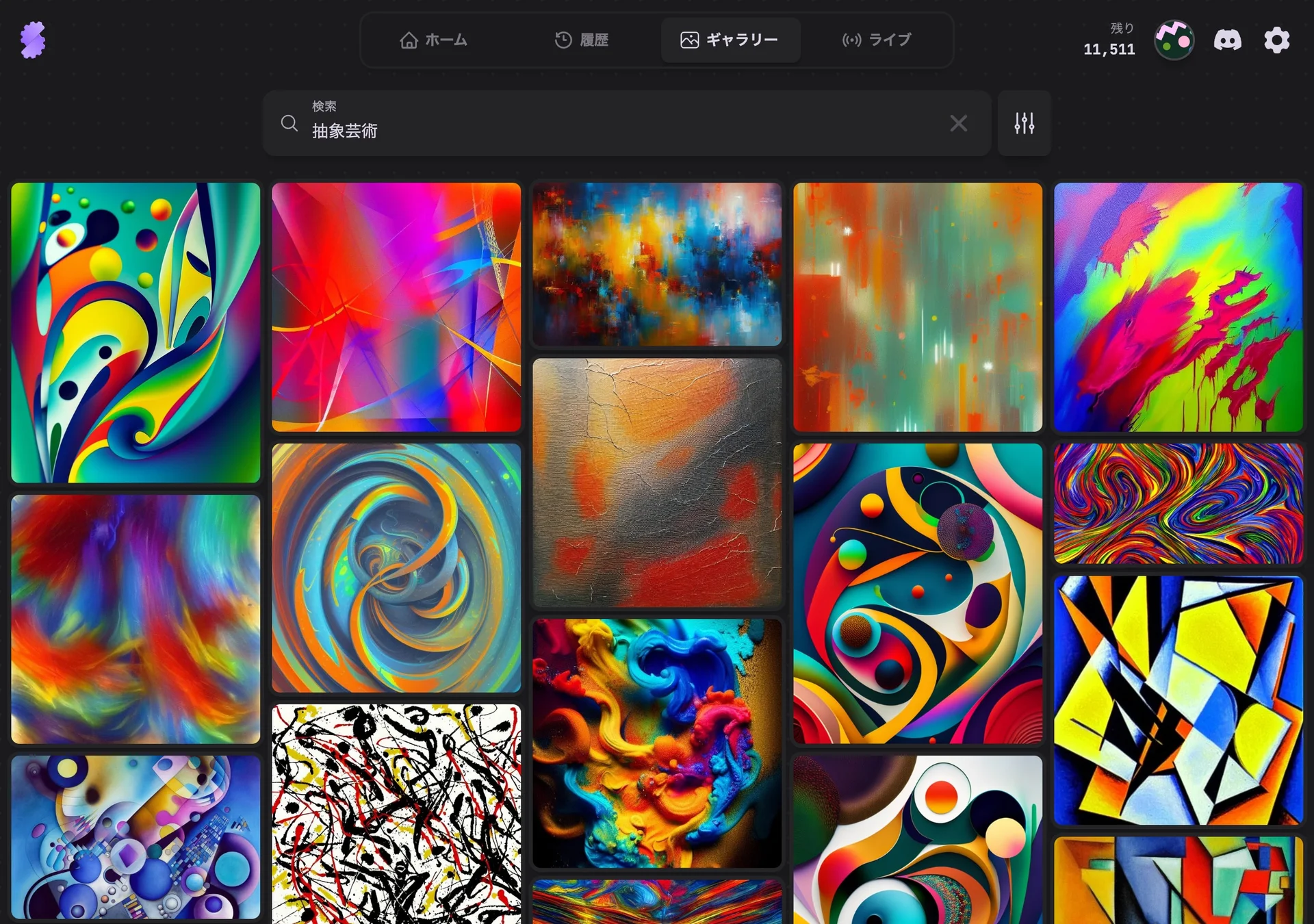
With our traditional search engine, the search query “a creature with 8 legs” wouldn’t return images of spiders. Because the old system would search based on words not meaning. Thanks to semantic search, we can now return images of spiders, and other 8 legged creatures even if the search query doesn’t directly mention “a spider”. Here are some examples:
English - A creature with 8 legs
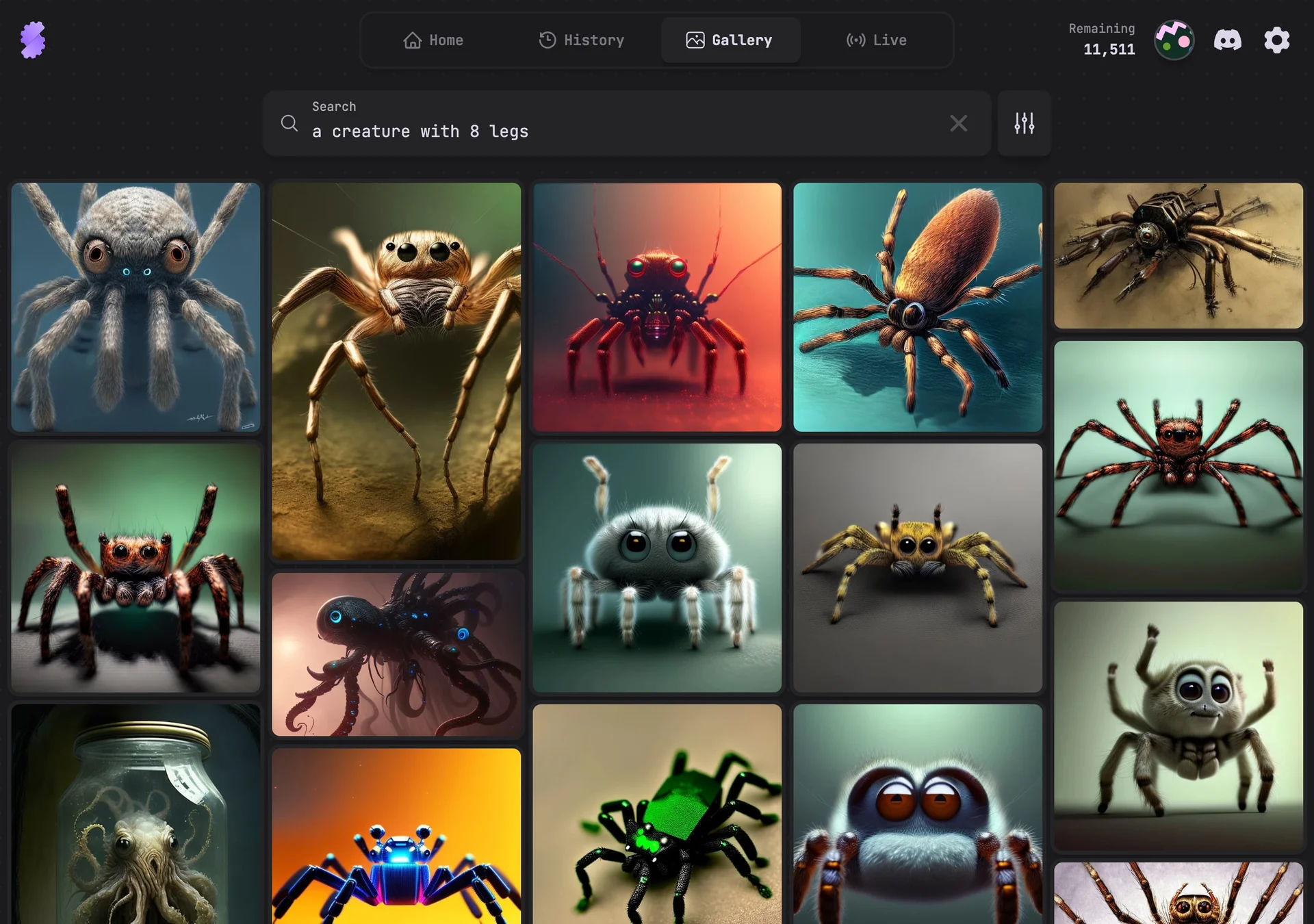
Turkish - Sarı veya yeşil saçlı bir kadın
Translation: A woman with yellow or green hair
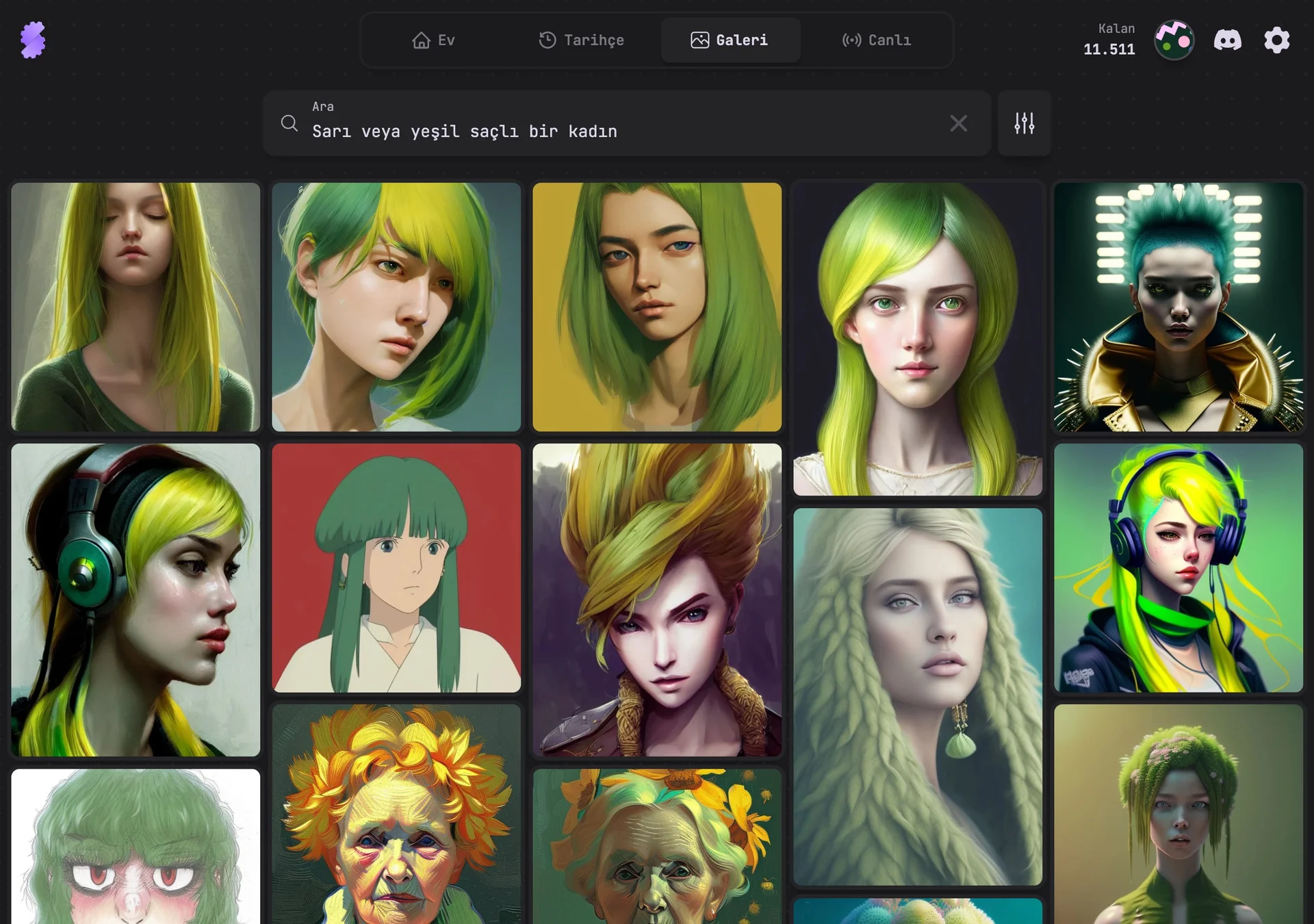
Japanese - 抽象芸術
Translation: Abstract art